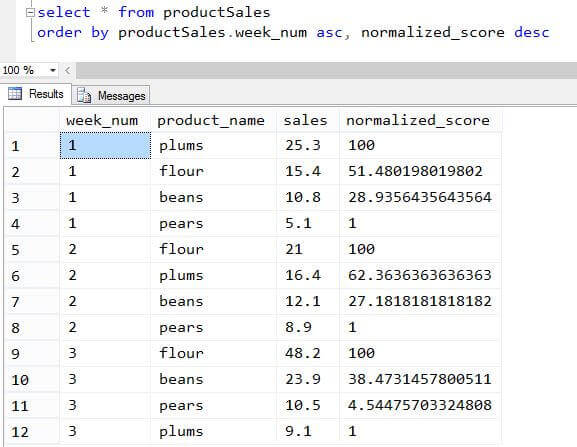
In T-SQL, you summarize data by using the GROUP BY clause within an aggregate query. This clause creates groupings which are defined by a set of expressions. One row per unique combination of the expressions in the GROUP BY clause is returned, and aggregate functions such as COUNT or SUM may be used on any columns in the query. However, if you want to group the data by multiple combinations of group by expressions, you may take one of two approaches. The first approach is to create one grouped query per combination of expressions and merge the results using the UNION ALL operator.

The other approach is to use the GROUPING SETS operator along with the GROUP BY clause and define each grouping set within a single query. ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions. Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on. Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set.

The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. In the result set, the order of columns is the same as the order of their specification by the select expressions.

If a select expression returns multiple columns, they are ordered the same way they were ordered in the source relation or row type expression. Like most things in SQL/T-SQL, you can always pull your data from multiple tables. Performing this task while including a GROUP BY clause is no different than any other SELECT statement with a GROUP BY clause. The fact that you're pulling the data from two or more tables has no bearing on how this works.

In the sample below, we will be working in the AdventureWorks2014 once again as we join the "Person.Address" table with the "Person.BusinessEntityAddress" table. I have also restricted the sample code to return only the top 10 results for clarity sake in the result set. The SQL GROUP BY clause allows us to group individual data based on defined criteria.
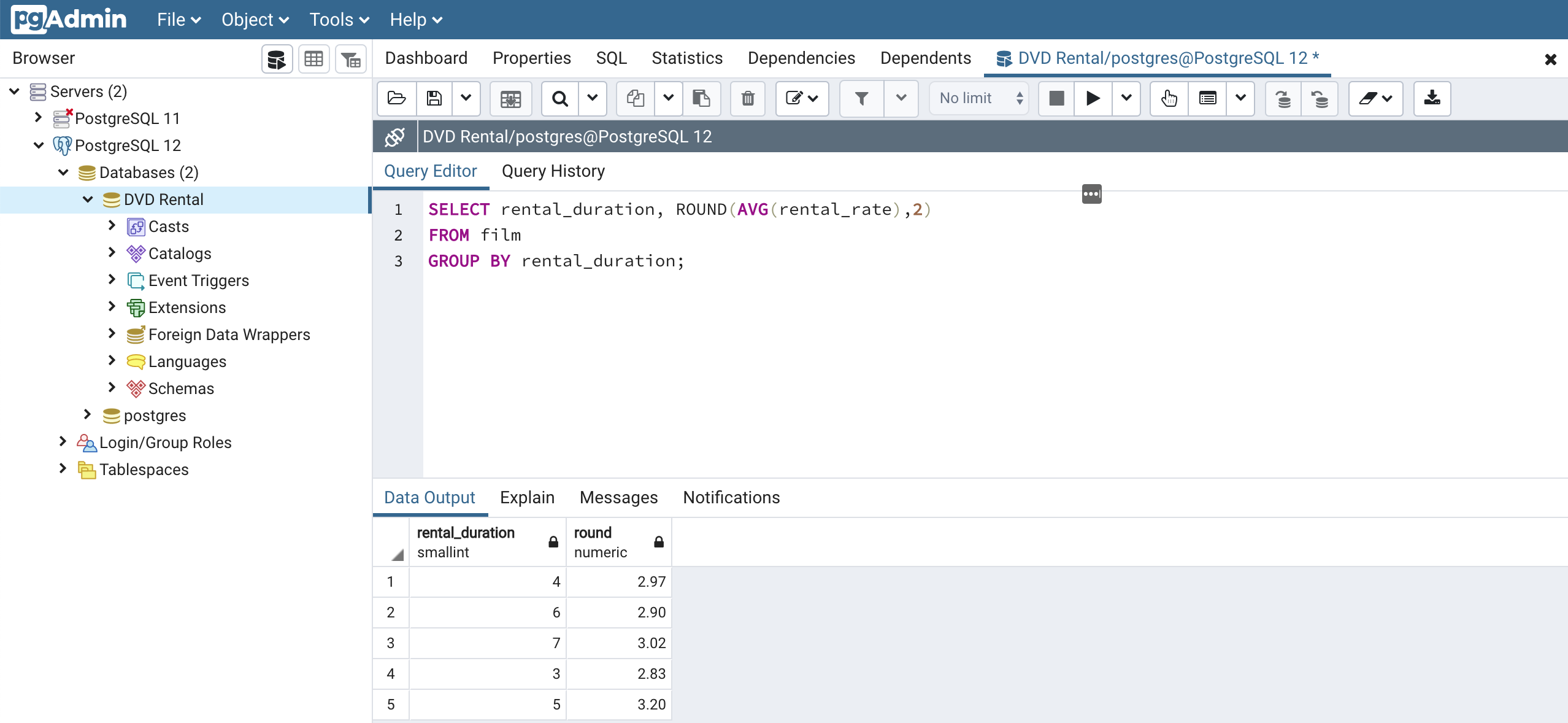
You can group individual data by one or more table columns. In order to do the grouping properly, you often need to apply aggregate functions to the column within the SQL SELECT statement. In the database world, static data is not typically stored.

Instead, it keeps changing when we update existing data, archive or delete irrelevant data and more. For example, let's say you have a table that stores product pricing data for your shopping portal. The product prices constantly change, as you might offer product discounts at different times to your customers.

In this case, you cannot add new rows in the table because the product record already exists, but you are required to update the current prices for existing products. The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. The SUM() function returns the total value of all non-null values in a specified column. Since this is a mathematical process, it cannot be used on string values such as the CHAR, VARCHAR, and NVARCHAR data types.

When used with a GROUP BY clause, the SUM() function will return the total for each category in the specified table. IIt is important to note that using a GROUP BY clause is ineffective if there are no duplicates in the column you are grouping by. A better example would be to group by the "Title" column of that table. The SELECT clause below will return the six unique title types as well as a count of how many times each one is found in the table within the "Title" column.
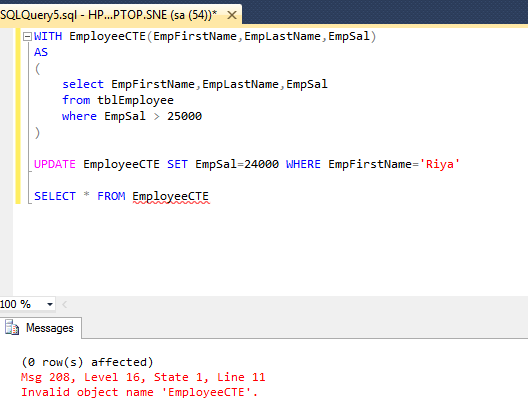
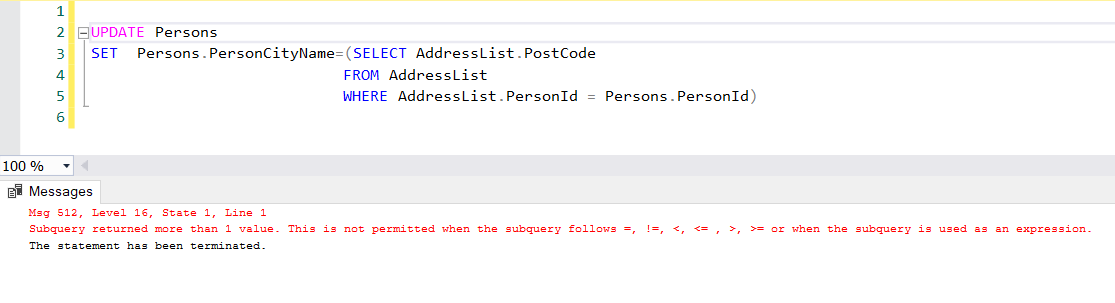
No WHERE clause is needed, as the INNER JOIN already filters the data we need for the query. In some cases, where the logic becomes more complex, you might need to resort to subqueries orcommon table expressions . For example, the following query returns an error since you cannot directly aggregate in the SET list of the UPDATE statement.
We can use the Update statement with Left Join as well, and it updates the records with NULL values. As highlighted earlier, we cannot use a single Update statement for updating multiple columns from different tables. The GROUP BY clause arranges rows into groups and an aggregate function returns the summary (count, min, max, average, sum, etc.,) for each group. In the sample below, we will return a list of the "CountryRegionName" column and the "StateProvinceName" from the "Sales.vSalesPerson" view in the AdventureWorks2014 sample database. In the first SELECT statement, we will not do a GROUP BY, but instead, we will simply use the ORDER BY clause to make our results more readable sorted as either ASC or DESC.
The previous query will not work without a GROUP BY clause since it contains an aggregate function. Insert a GROUP BY clause and use the Location column for grouping. Since the column contains five different values , the final query result will have five rows. You can use any method specified in this article for performing UPDATE from SELECT statements.
The subquery works efficiently, but it has its own limitations, as highlighted earlier. The overall performance of your database depends on the table data, the number of updates, table relationships,indexes, and statistics. The subquery with a comparison operator can include only one column name except if it used for the IN or EXISTS operator. Therefore, if we require updating multiple columns of data, we need separate SQL statements. In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement. You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used.
An aggregate function performs a calculation on a group and returns a unique value per group. For example, COUNT() returns the number of rows in each group. Other commonly used aggregate functions are SUM(), AVG() , MIN() , MAX() .

Contrary to what most books and classes teach you, there are actually 9 aggregate functions, all of which can be used with a GROUP BY clause in your code. As we have seen in the samples above, you can have a GROUP BY clause without an aggregate function as well. As we demonstrated earlier in this article, the GROUP BY clause can group string values also, so it doesn't always have to be a numeric or date value. Another extension, or sub-clause, of the GROUP BY clause is the CUBE. The CUBE generates multiple grouping sets on your specified columns and aggregates them. In short, it creates unique groups for all possible combinations of the columns you specify.
For example, if you use GROUP BY CUBE on of your table, SQL returns groups for all unique values , , and . The UPDATE statement can only reference columns from one base table. This means it's not possible to update multiple tables at once using a single UPDATE statement.

Grouping with a Case Statement Build a CASE STATEMENT to GROUP a column with an alias or new string. Using GROUP BY allows you to divide rows returned from the SELECT statement into groups. The GROUP BY statement is often used with aggregate functions (COUNT(),MAX(),MIN(), SUM(),AVG()) to group the result-set by one or more columns. Again, the query from the previous step won't work without a GROUP BY clause since it contains an aggregate function.

You now apply a GROUP BY clause on both the Location and Department columns. First, you group data by location; then you group those locations by department, effectively creating department subgroups within the location groups. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns.
WE can use aggregate functions like sum, min, max, avg, etc with the HAVING clause but they can never be used with WHERE clause. However, if you still want more details about the company's income, you must perform a new grouping by adding a column or expression to the GROUP BY clause. Add the order month to the previous set of group by expressions. By doing this, the query will return the company's income per year and month. Writing aggregate queries is one of the most important tasks for anyone working with T-SQL.
Alfonso demonstrates how to use the GROUPING SETS operator to accomplish this task. This is an important point a SQL developer must understand to avoid a common error when using the GROUP BY clause. After the database creates the groups of records, all the records are collapsed into groups.

You can no longer refer to any individual record column in the query. In the SELECT list, you can only refer to columns that appear in the GROUP BY clause. The columns appearing in the group are valid because they have the same value for all the records in the group.

A best practice would be to create a view from the above SELECT statement to save time and provide a more efficient way of grouping on the table that have these deprecated data types. Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses. If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions. It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above. In the next sample code block, we are now referencing the "Sales.SalesOrderHeader" table to return the total from the "TotalDue" column, but only for a particular year. As you can see in the result set above, the query has returned all groups with unique values of , , and .
The NULL NULL result set on line 11 represents the total rollup of all the cubed roll up values, much like it did in the GROUP BY ROLLUP section from above. With the character data types CHAR(), VARCHAR(), and NVARCHAR(), the MIN() function sorts the string values alphabetically and returns the first value in the alphabetized list. The MIN() function returns the smallest value in the column specified. The SQL Server (Transact-SQL) UPDATE statement is used to update existing records in a table in a SQL Server database.

There are 3 syntaxes for the UPDATE statement depending on whether you are performing a traditional update or updating one table with data from another table. Clause separates rows into different groups for aggregate functions. In this tutorial, you have learned how to use the MariaDB update statement to modify data of the existing rows in a table.

Third, use an optional where clause to specify which rows you want to modify data. If you skip the where clause, the update statement will modify the data of all rows in the table. The second table columns gets updated by taking data from first table. Let us say we have one table where students test marks are stored along with other details in other columns.

We can collect only the test data and keep them in a separate table. Both the tables will have student id field which we will be using to link both tables. In this article, you learned how to achieve an aggregate query with more than one grouping expression list by using the GROUPING SETS operator. Unlike other operators such as ROLLUP and CUBE, you must specify each grouping set. These grouping operators are very important for summarizing data and producing grand totals and sub totals. If you want more information about these operators, please read this article.

The count() function is an aggregate function use to find the count of the rows that satisfy the fixed conditions. The count() function with the GROUP BY clause is used to count the data which were grouped on a particular attribute of the table. WeWe added a "WHERE" clause to cull out any NULL valued rows. Since T-SQL ignores any NULL valued rows, it makes this WHERE clause purely cosmetic in nature. Had we left out the WHERE clause, the returned values would remain the same for all rows, except for the additional row representing the NULL values.

The sample below shows the results without the WHERE clause. An ORDER BY clause was not used in this sample and as you can see there is no order to the result set. If you need to use an ORDER BY clause, it must follow the GROUP BY clause. The other item you may notice in the above query, is that we used a WHERE filter to cull out any rows that are NULL.
If you want to include the rows that are NULL, simply remove the WHERE clause from the query. All column names listed in the SELECT command must also appear in the GROUP BY statement whether you have an aggregate function or not. The GROUP BY clause will break all 20 rows into three groups and return only three rows of data, one for each group. In simpler terms, the GROUP BY clause combines rows into groups based on matching data in specified columns of a table.
The view columns that are modified must directly reference the data of the base table. This means an aggregation function cannot be used, or any other expression using other columns. Using UNION or other set operators are also prohibited. In general, it's a best practice to restrict the rows you want to update, for performance reasons but also to avoid overwriting data that shouldn't have been updated. When running an UPDATE query on a production server, you don't want to forget your WHERE clause. It's possible to reference columns of the same table, while they are being updated as well.




